

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
SiteFusion & EBCONT zu Gast beim Event AI@media 2021
Am 16.09.2021 – 17.09.2021 fand die Digitalkonferenz AI@media statt. Die beiden Publishing-Spezialisten Thomas Weinberger (Geschäftsführer SiteFusion) und Gregor Sieber (Head of Consulting and Innovation EBCONT) präsentierten, wie die Integration von Künstlicher Intelligenz in verschiedensten Prozessen von Verlagen zur Einsparung von Kosten und Zeit führt. Drei interessante Fallbeispiele, direkt aus dem Arbeitsalltag gemeinsamer Kunden, dienten als erste Impulse für einen regen Austausch im anschließenden Workshop. Teilnehmende hatten die Chance, ihre wohldurchdachten Ideen oder spontanen Geistesblitze mit den Verlagsexperten zu teilen und erhielten wertvolle Tipps, individuelle Handlungsempfehlungen und umsetzbare Möglichkeiten im eigenen Unternehmen. Das Konferenz- und Workshop-Ereignis AI@media, veranstaltet vom DIGITAL PUBLISHING REPORT und Alexander Pinker Innovation-Profiling, umfasste zwei Tage voll spannender Infos, Erfahrungsberichte und die Demonstration neuer Technologien. Der Vortrag mit anschließendem Deep Dive Workshop „Automatisierung mit KI im Content- und Asset Workflow – welche Schritte möchten Sie in Zukunft nicht mehr von Hand machen?“ fand am 17.09.2021 statt.
Die Transformation von Unternehmen durch Künstliche Intelligenz kann über mehrere Schritte hinweg erfolgen. Integrationspartner EBCONT zeigte den groben Ablauf auf, den Verlage durchlaufen, um erfolgreich Machine Learning oder KI im Arbeitsalltag gewinnbringend einzusetzen.
Start
Bereits existierenden, neu erfassten & externen Content, Assets & Daten sammeln.
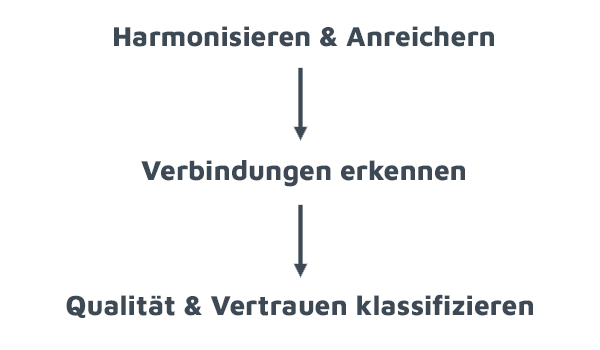
![]()
Alles geschieht immer in Verbindung und Kommunikation mit einem Operational Data Hub/ Data Lake (zum Beispiel das CMS SiteFusion).
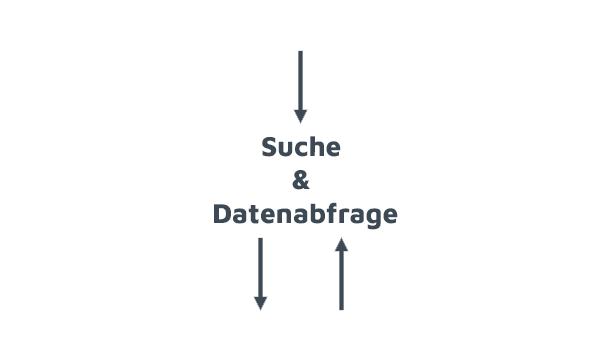
Nun können die Daten in weitere Tools weitergegeben werden oder weitere Methoden angewendet werden, um die definierten Ziele im Bereich der Automatisierung durch KI zu erreichen.
- Datengesteuerte Business Apps
- Visualisierungs- und Analytics-Tools
- Data Science & Machine Learning
Welche Prozesse können nun mit KI-Automatisierungen effizienter gestaltet werden?
Lesen Sie hier verschiedenste Use Cases im Umgang mit Media Assets und Kategorisierungen von Inhalten und erfahren Sie wie SiteFusion und EBCONT diese bereits erfolgreich in der Praxis umsetzen.
Informationen aus Media Assets extrahieren und nutzen: Verschlagwortung von Bildern
Unzählige Media Assets, wie beispielsweise Bilder, werden täglich in Systeme (DAM/ MAM/ CMS) hochgeladen. Bilder enthalten visuell eine Vielzahl an Informationen. Es ist eine zeitraubende Aufgabe für Publisher, jedes Bild manuell mit Schlagwörtern in den Metadaten zu versehen und diese Informationen immer up-to-date und umfangreich durchsuchbar zu halten.
Diesen Schritt möchte ich in Zukunft nicht mehr von Hand machen!
Die Lösung: EBCONT und SiteFusion bieten hierfür einen schlanken und effizienten Workflow an, der diese mühselige Arbeit durch eine automatisierte Verschlagwortung ersetzt. Sparen Sie sich den manuellen Aufwand dieses Taggings. Durch den Workflow werden die Media Assets an die Cloud Services der „Google Vision API“ geschickt. Innerhalb nur weniger Sekunden wird das Motiv des/der ausgewählte(n) Bild(er) erkannt und im Anschluss die Tags an SiteFusion zurückgegeben und in der MarkLogic Datenbank gespeichert. Sofort werden qualitativ hochwertige und vielzählige Schlagwörter in den Metadaten der Bilder hinterlegt. An dieser Stelle werden semantische Netzwerke verknüpft und genutzt. Hier haben Publisher die Möglichkeit, selbst perfekt individuelle Netze zu entwickeln oder bereits vollumfängliche Netzwerke in den verschiedensten Bereiche zu erwerben und unendlich zu erweitern. Selbstverständlich sind Alternativen zur Google Vision API möglich.
Aufgepasst! Diese KI-Automatisierung ist bereits Out-of-the-box und mit sehr geringem Initialaufwand in SiteFusion verfügbar.
Informationen aus Media Assets extrahieren und nutzen: Tonspur von Media Assets erfassen
Media Assets mit Tonspur wie zum Beispiel Videos und Audiodateien werden in Systeme (DAM/ MAM/ CMS) hochgeladen oder befinden sich dort schon. Damit die Inhalte dieser Assets nicht verborgen bleiben, ist es sehr aufwendig, Wort-für-Wort manuell die Tonspur zu analysieren und niederzuschreiben. Ohne diese Erfassung der Tonspur ist es lediglich möglich, die Datenbank nach technischen Daten und Dateinamen der Assets zu durchsuchen.
Diesen Schritt möchte ich in Zukunft nicht mehr von Hand machen!
Die Lösung: Auch hier bietet EBCONT und SiteFusion eine Möglichkeit, wie Tonspuren automatisch und durch Künstliche Intelligenz ausgelesen werden können. Durch die Cloudanbindung „Google Speech API“ werden Inhalte dieser Art als Teil von Media Assets ohne manuellen Aufwand komplett erfasst. Alle Inhalte der Tonspur können durch eine Suche oder Datenabfrage gefunden werden. Eine automatische Aussteuerung auf Basis der Metadaten in verschiedenste Produkte und Kanäle ist damit auch sehr leicht möglich. Nutzen Sie die Inhalte auch, um zum Beispiel Rückschlüsse auf die Vorlieben von einzelnen User-Profilen Ihrer Themenportale oder Apps zu ziehen. Welche Nutzer:innen haben Interesse an bestimmten Videos und Audios? Dies kann in Ihre Content- und Produktplanung der Zukunft miteinfließen.
Inhalte von Media Assets extrahieren und nutzen: Textinhalte aus Bildern extrahieren
In Media Assets stecken wichtige Informationen in Form von Texten oder Wörtern. Bei einer Datenmigration in ein neues System (DAM/ MAM/ CMS) oder aber auch sobald Publisher ihren Datenschatz besser nutzbar machen wollen, werden diese Infos als Metadaten benötigt. Es ist zum Beispiel notwendig, die Titel von Produkten aus den Covers abzulesen und in den jeweiligen Metadaten gesammelt zu hinterlegen. Angenommen die Titel der Werke befinden sich in der oberen Hälfte des Bildes in einer Box und grenzen sich visuell von den anderen Gestaltungselemente ab. Diese Aufgabe der manuellen Inhaltsextraktion kann ein Redaktionsteam viel Zeit kosten und wird sie längere Zeit auslasten.
Diesen Schritt möchte ich in Zukunft nicht mehr von Hand machen!
Die Lösung: Durch automatische Texterkennung auf optischer Zeichenerkennung (englisch: optical character recognition (OCR)) können Metadaten automatisiert aus Bildern extrahiert werden. Dadurch, dass der zu extrahierende Text sich von den anderen Gestaltungselementen und Texten des Bildes unterscheidet, kann dieser exakt von den Algorithmen der KI-Tools erkannt werden. Passende KI-Bibliotheken werden dafür herangezogen, wodurch Bereiche und Bildstrukturen in Bildern identifiziert werden.
Dies kann auf Basis von verschiedenen Features geschehen:
- Linien im Bild
- Farbgradienten im Bild
- Abstand zu anderem Text in Bild
- … und vieles mehr
Nachdem dieser Bereich identifiziert wurde, werden diese Informationen und Koordinaten an OCR weitergegeben. Dadurch können bestimmte Textinhalte aus Bildern automatisch extrahiert werden.
Inhalte von Media Assets extrahieren und nutzen: Beschneidung von Bildern
Es gibt Teile oder Bereiche von Bildern, die fortlaufend nicht mehr benötigt werden und daher entfernt werden müssen. Es soll zum Beispiel bei einer großen Anzahl an Bildern eine Box mit einem Icon weggeschnitten werden. Auch hier muss jedes einzelne Media Asset begutachtet und manuell wiederholt beschnitten werden.
Diesen Schritt möchte ich in Zukunft nicht mehr von Hand machen!
Die Lösung: Auch hier kann durch KI-Bibliotheken, die oftmals schon als Open Source verfügbar sind und OCR eine automatische Beschneidung veranlasst werden. Wie bei der Inhaltsextraktion von Texten aus Bildern, werden hier Bildstrukturen und Bildbereiche in den Bildern identifiziert. Es ist durch Künstliche Intelligenz nicht nur möglich, auf Basis von Bildkoordinaten zuzuschneiden, sondern auch dynamisch auf Basis von verschiedenen Features im Bild, die sich von dem Bereich visuell unterscheiden. Nach der Identifikation dieser Bereiche, die zugeschnitten werden sollen, werden auch hier diese Informationen an OCR weitergegeben. Die Bilder werden so automatisch passend zugeschnitten.
Inhaltskategorisierung: Dokumente, Scans und mehr kategorisieren
Bei einer Datenmigration aber auch wenn Publisher ihren Daten besser nutzbar machen wollen, ist eine Kategorisierung von Inhalten sehr hilfreich oder oftmals dringend notwendig. Inhalte sind aber in den meisten Fällen in unterschiedlicher Qualität oder Machart verfügbar. Redaktionelle Texte in digitaler Form (z.B. XML-Dateien), gescannte Dokumente, Bilder, PDFs – alles kann Inhalte enthalten, die eine Zuordnung benötigen. Mitarbeiter:innen stellen hier Methoden oder Modelle auf, nach denen die Inhalte kategorisiert werden sollen und nehmen diese Kategorisierung manuell vor. Die sortierten Inhalte werden dann an einer neuen Stelle geordnet, verankert oder zugewiesen. Diese Kategorisierung ist sehr aufwendig und setzt voraus, dass alle involvierten Mitarbeiter:innen in die Modelle eingewiesen werden.
Diesen Schritt möchte ich in Zukunft nicht mehr von Hand machen!
Die Lösung: Umfangreiche und granuale Kategorisierungsmodelle werden auf Basis von bereits manuell kategorisierten Inhalten aufgebaut. Diese Erstellung der Modelle kann auch als iterativer Prozess stattfinden und stetig weiterentwickelt werden. Durch eine Kombination an Tools, wie beispielsweise OCR für gescannte Dokumente, können Inhalte automatisch zugeordnet werden. Neben den eigenen Inhalten können selbstverständlich auch andere Inhalte kategorisiert werden. Auch hier können diese Informationen für die eigene Content- und Produktplanung genutzt werden oder in Kanäle zum Monitoring geleitet werden. Ordnen Sie beispielsweise Kommentare oder Feedback von Nutzer:innen auf eigenen Sozialen Medien oder Themenportalen nach verschiedenen Themen oder Kategorien.
Sie stehen vor ähnlichen Herausforderungen?
Sie fragen sich, ob diese automatisierten Schnitte auch für Sie möglich und erschwinglich sind?
Nehmen Sie gerne Kontakt zu uns auf!
Sie möchten an weiteren spannenden Events teilnehmen?
Finden Sie die neusten Informationen auf unserer Website und auf LinkedIn.

